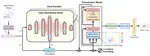
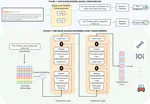
We present HyWay, short for “Hybrid Hallway”, to enable mingling and informal interactions among physical and virtual users, in casual spaces and settings, such as office water cooler areas, conference hallways, trade show floors, and more.
Harsh Vijay, Saumay Pushp, Amish Mittal, Praveen Gupta, Meghna Gupta, Sirish Gambhira, Shivang Chopra, Mayank Baranwal, Arshia Arya, Ajay Manchepalli, Venkata N Padmanabhan